Over the past few months, James Henstridge, Xavi Garcia Mena, and I have implemented a fast and scalable thumbnailing service for Ubuntu and Ubuntu Touch. This post explains how we did it, and how we achieved our performance and reliability goals.
Introduction
On a phone as well as the desktop, applications need to display image thumbnails for various media, such as photos, songs, and videos. Creating thumbnails for such media is CPU-intensive and can be costly in bandwidth if images are retrieved over the network. In addition, different types of media require the use of different APIs that are non-trivial to learn. It makes sense to provide thumbnail creation as a platform API that hides this complexity from application developers and, to improve performance, to cache thumbnails on disk.
This article explains the requirements we had and how we implemented a thumbnailer service that is extremely fast and scalable, and robust in the face of power loss or crashes.
Requirements
We had a number of requirements we wanted to meet in our implementation.
- Robustness
In the event of a crash, the implementation must guarantee the integrity of on-disk data structures. This is particularly important on a phone, where we cannot expect the user to perform manual recovery (such as cleaning up damaged files). Because batteries can run out at any time, integrity must be guaranteed even in the face of power loss.
- Scalability
It is common for people to store many thousands of songs and photos on a device, so the cache must scale to at least tens of thousands of records. Thumbnails can range in size from a few kilobytes to well over a megabyte (for “thumbnails” at full-screen resolution), so the cache must deal efficiently with large records.
- Re-usability
Persistent and reliable on-disk storage of arbitrary records (ranging in size from a few bytes to potentially megabytes) is a common application requirement, so we did not want to create a cache implementation that is specific to thumbnails. Instead, the disk cache is provided as a stand-alone C++ API that can be used for any number of other purposes, such as a browser or HTTP cache, or to build an object file cache similar to ccache.
- High performance
The performance of the thumbnailer directly affects the user experience: it is not nice for the customer to look at “please wait a while” icons in, say, an image gallery while thumbnails are being loaded one by one. We therefore had to have a high-performance implementation that delivers cached thumbnails quickly (on the order of a millisecond per thumbnail on an Arm CPU). An efficient implementation also helps to conserve battery life.
- Location independence and extensibility
Canonical runs an image server at dash.ubuntu.com that provides album and artist artwork for many musicians and bands. Images from this server are used to display artwork in the music player for media that contains ID3 tags, but does not embed artwork in the media file. The thumbnailer must work with embedded images as well as remote images, and it must be possible to extend it to new media types without unduly disturbing the existing code.
- Low bandwidth consumption
Mobile phones typically come with data caps, so the cache has to be frugal with network bandwidth.
- Concurrency and isolation
The implementation has to allow concurrent access by multiple applications, as well as concurrent access from a single implementation. Besides needing to be thread-safe, this means that a request for a thumbnail that is slow (such as downloading an image over the network) must not delay other requests.
- Fault tolerance
Mobile devices lose network access without warning, and users can add corrupt media files to their device. The implementation must be resilient to partial failures, such as incomplete network replies, dropped connections, and bad image data. Moreover, the recovery strategy for such failures must conserve battery and avoid repeated futile attempts to create thumbnails from media that cannot be retrieved or contains malformed data. - Security
The implementation must ensure that applications cannot see (or, worse, overwrite) each other’s thumbnails or coerce the thumbnailer into delivering images from files that an application is not allowed to read.
- Asynchronous API
The customers of the thumbnailer are applications that are written in QML or Qt, which cannot block in the UI thread. The thumbnailer therefore must provide a non-blocking API. Moreover, the application developer should be able to get the best possible performance without having to use threads. Instead, concurrency must be internal to the implementation (which is able to put threads to use intelligently where they make sense), instead of the application throwing threads at the problem in the hope that it might make things faster when, in fact, it might just add overhead.
- Monitoring
The effectiveness of a cache cannot be assessed without statistics to show hit and miss rates, evictions, and other basic performance data, so it must provide a way to extract this information.
- Error reporting
When something goes wrong with a system service, typically the only way to learn about the problem is to look at log messages. In case of a failure, the implementation must leave enough footprints behind to allow someone to diagnose a failure after the fact with some chance of success.
- Backward compatibility
This project was a rewrite of an earlier implementation. Rather than delivering a “big bang” piece of software and potentially upsetting existing clients, we incrementally changed the implementation such that existing applications continued to work. (The only pre-existing interface was a QML interface that required no change.)
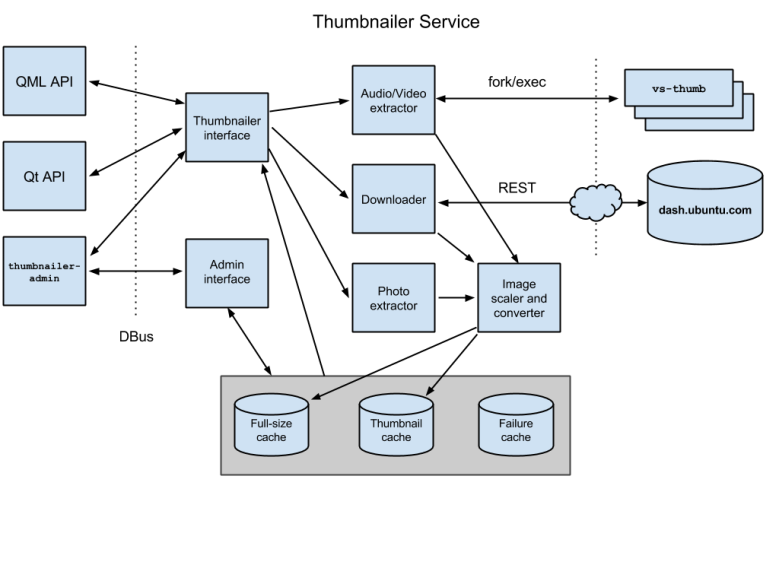
System architecture
Here is a high-level overview of the main system components.
 External API
External API

To the outside world, the thumbnailer provides two APIs.
One API is a QML plugin that registers itself as an image provider for QQuickAsyncImageProvider. This allows the caller to to pass a URI that encodes a query for a local or remote thumbnail at a particular size; if the URI matches the registered provider, QML transfers control to the entry points in our plugin.
The second API is a Qt API that provides three methods:
QSharedPointer<Request> getThumbnail(QString const& filePath, QSize const& requestedSize); QSharedPointer<Request> getAlbumArt(QString const& artist, QString const& album, QSize const& requestedSize); QSharedPointer<Request> getArtistArt(QString const& artist, QString const& album, QSize const& requestedSize);
The getThumbnail() method extracts thumbnails from local media files, whereas getAlbumArt() and getArtistArt() retrieve artwork from the remote image server. The returned Request object provides a finished signal, and methods to test for success or failure of the request and to extract a thumbnail as a QImage. The request also provides a waitForFinished() method, so the API can be used synchronously.
Thumbnails are delivered to the caller in the size they are requested, subject to a (configurable) 1920-pixel limit. The scaling algorithm preserves the original aspect ratio and never scales up from the original, so the returned thumbnails may be smaller than their requested size.
DBus service
The thumbnailer is implemented as a DBus service with two interfaces. The first interface provides the server-side implementation of the three methods of the external API; the second interface is an administrative interface that can deliver statistics, clear the internal disk caches, and shut down the service. A simple tool, thumbnailer-admin, allows both interfaces to be called from the command line.
To conserve resources, the service is started on demand by DBus and shuts down after 30 seconds of idle time.
Image extraction
Image extraction uses an abstract base class. This interface is independent of media location and type. The actual image extraction is performed by derived implementations that download images from the remote server, extract them from local image files, or extract them from local streaming media files. This keeps knowledge of image location and encoding out of the main caching and error handling logic, and allows us to support new media types (whether local or remote) by simply adding extra derived implementations.
Image extraction is asynchronous, with currently three implementations:
- Image downloader
To retrieve artwork from the remote image server, the service talks to an abstract base class with asynchronous download_album() and download_artist() methods. This allows multiple downloads to run concurrently and makes it easy to add new local or remote image providers without disturbing the code for existing ones. A class derived from that abstract base implements a REST API with QNetworkAccessManager to retrieve images from dash.ubuntu.com.
- Photo extractor
The photo extractor is responsible for delivering images from local image files, such as JPEG or PNG files. It simply delegates that work to the image converter and scaler.
- Audio and video thumbnail extractor
To extract thumbnails from audio and video files, we use GStreamer. Due to reliability problems with some codecs that can hang or crash, we delegate the task to a separate vs-thumb executable. This shields the service from failures and also allows us to run several GStreamer pipelines concurrently without a crash of one pipeline affecting the others.
Image converter and scaler
We use a simple Image class with a synchronous interface to convert and scale different image formats to JPEG. The implementation uses Gdk-Pixbuf, which can handle many different input formats and is very efficient.
For JPEG source images, the code checks for the presence of EXIF data using libexif and, if it contains a thumbnail that is at least as large as the requested size, scales the thumbnail from the EXIF data. (For images taken with the camera on a Nexus 4, the original image size is 3264×1836, with an embedded EXIF thumbnail of 512×288. Scaling from the EXIF thumbnail is around one hundred times faster than scaling from the full-size image.)
Disk cache
The thumbnailer service optimizes performance and conserves bandwidth and battery by adopting a layered caching strategy.
Two-level caching with failure lookup
Internally, the service uses three separate on-disk caches:
- Full-size cache
This cache stores images that are expensive to retrieve (images that are remote or are embedded in audio and video files) at original resolution (scaled down to a 1920-pixel bounding box if the original image is larger). The default size of this cache is 50 MB, which is sufficient to hold around 400 images at 1920×1080 resolution. Images are stored in JPEG format (at a 90% quality setting). - Thumbnail cache
This cache stores thumbnails at the size that was requested by the caller, such as 512×288. The default size of this cache is 100 MB, which is sufficient to store around 11,000 thumbnails at 512×288, or around 25,000 thumbnails at 256×144. - Failure cache
The failure cache stores the keys for images that could not be extracted because of a failure. For remote images, this means that the server returned an authoritative answer “no such image exists”, or that we encountered an unexpected (non-authoritative) failure, such as the server not responding or a DNS lookup timing out. For local images, it means either that the image data could not be processed because it is damaged, or that an audio file does not contain embedded artwork.
The full-size cache exists because it is likely that an application will request thumbnails at different sizes for the same image. For example, when scrolling through a list of songs that shows a small thumbnail of the album cover beside each song, the user is likely to select one of the songs to play, at which point the media player will display the same cover in a larger size. By keeping full-size images in a separate (smallish) cache, we avoid performing an expensive extraction or download a second time. Instead, we create additional thumbnails by scaling them from the full-size cache (which uses an LRU eviction policy).
The thumbnail cache stores thumbnails that were previously retrieved, also using LRU eviction. Thumbnails are stored as JPEG at the default quality setting of 75%, at the actual size that was requested by the caller. Storing JPEG images (rather than, say, PNG) saves space and increases cache effectiveness. (The minimal quality loss from compression is irrelevant for thumbnails). Because we store thumbnails at the size they are actually needed, we may have several thumbnails for the same image in the cache (each thumbnail at a different size). But applications typically ask for thumbnails in only a small number of sizes, and ask for different sizes for the same image only rarely. So, the slight increase in disk space is minor and amply repaid by applications not having to scale thumbnails after they receive them from the cache, which saves battery and achieves better performance overall.
Finally, the failure cache is used to stop futile attempts to repeatedly extract a thumbnail when we know that the attempt will fail. It uses LRU eviction with an expiry time for each entry.
Cache lookup algorithm
When asked for a thumbnail at a particular size, the lookup and thumbnail generation proceed as follows:
- Check if a thumbnail exists in the requested size in the thumbnail cache. If so, return it.
- Check if a full-size image for the thumbnail exists in the full-size cache. If so, scale the new thumbnail from the full-size image, add the thumbnail to the thumbnail cache, and return it.
- Check if there is an entry for the thumbnail in the failure cache. If so, return an error.
- Attempt to download or extract the original image for the thumbnail. If the attempt fails, add an entry to the failure cache and return an error.
- If the original image was delivered by the remote server or was extracted from local media, add it to the full-size cache.
- Scale the thumbnail to the desired size, add it to the thumbnail cache, and return it.
Note that these steps represent only the logical flow of control for a particular thumbnail. The implementation executes these steps concurrently for different thumbnails.
Designing for performance
Apart from fast on-disk caches (see below), the thumbnailer must make efficient use of I/O bandwidth and threads. This not only means making things fast, but also to not waste resources such as threads, memory, network connections, or file descriptors. Provided that enough requests are made to keep the service busy, we do not want it to ever wait for a download or image extraction to complete while there is something else that could be done in the mean time, and we want it to keep all CPU cores busy. In addition, requests that are slow (because they require a download or a CPU-intensive image extraction) must not block requests that are queued up behind them if those requests would result in cache hits that could be returned immediately.
To achieve a high degree of concurrency without blocking on long-running operations while holding precious resources, the thumbnailer uses a three-phase lookup algorithm:
- In phase 1, we look at the caches to determine if we have a hit or an authoritative miss. Phase 1 is very fast. (It takes around a millisecond to return a thumbnail from the cache on a Nexus 4.) However, cache lookup can briefly stall on disk I/O or require a lot of CPU to extract and scale an image. To get good performance, phase 1 requests are passed to a thread pool with as many threads as there are CPU cores. This allows the maximum number of lookups to proceed concurrently.
- Phase 2 is initiated if phase 1 determines that a thumbnail requires download or extraction, either of which can take on the order of seconds. (In case of extraction from local media, the task is CPU intensive; in case of download, most of the time is spent waiting for the reply from the server.) This phase is scheduled asynchronously from an event loop. This minimizes task switching and allows large numbers of requests to be queued while only using a few bytes for each request that is waiting in the queue.
- Phase 3 is really a repeat of phase 1: if phase 2 produces a thumbnail, it adds it to the cache; if phase 2 does not produce a thumbnail, it creates an entry in the failure cache. By simply repeating phase 1, the lookup then results in either a thumbnail or an error.
If phase 2 determines that a download or extraction is required, that work is performed concurrently: the service schedules several downloads and extractions in parallel. By default, it will run up to two concurrent downloads, and as many concurrent GStreamer pipelines as there are CPUs. This ensures that we use all of the available CPU cores. Moreover, download and extraction run concurrently with lookups for phase 1 and 3. This means that, even if a cache lookup briefly stalls on I/O, there is a good chance that another thread can make use of the CPU.
Because slow operations do not block lookup, this also ensures that a slow request does not stall requests for thumbnails that are already in the cache. In other words, it does not matter how many slow requests are in progress: requests that can be completed quickly are indeed completed quickly, regardless of what is going on elsewhere.
Overall, this strategy works very well. For example, with sufficient workload, the service achieves around 750% CPU utilization on an 8-core desktop machine, while still delivering cache hits almost instantaneously. (On a Nexus 4, cache hits take a little over 1 ms while concurrent extractions or downloads are in progress.)
A re-usable persistent cache for C++
The three internal caches are implemented by a small and flexible C++ API. This API is available as a separate reusable PersistentStringCache component (see persistent-cache-cpp) that provides a persistent store of arbitrary key–value pairs. Keys and values can be binary, and entries can be large. (Megabyte-sized values do not present a problem.)
The implementation uses leveldb, which provides a very fast NoSQL database that scales to multi-gigabyte sizes and provides integrity guarantees. In particular, if the calling process crashes, all inserts that completed at the API level will be intact after a restart. (In case of a power failure or kernel crash, a few buffered inserts can be lost, but the integrity of the database is still guaranteed.)
To use a cache, the caller instantiates it with a path name, a maximum size, and an eviction policy. The eviction policy can be set to either strict LRU (least-recently-used) or LRU with an expiry time. Once a cache reaches its maximum size, expired entries (if any) are evicted first and, if that does not free enough space for a new entry, entries are discarded in least-recently-used order until enough room is available to insert a new record. (In all other respects, expired entries behave like entries that were never added.)
A simple get/put API allows records to be retrieved and added, for example:
auto c = core::PersistentStringCache::open(
“my_cache”, 100 * 1024 * 1024, core::CacheDiscardPolicy::lru_only);
// Look for an entry and add it if there is a cache miss. string key = "Bjarne"; auto value = c->get(key); if (value) { cout << key << ″: ″ << *value << endl; } else { value = "C++ inventor"; // Provide a value for the key. c->put(key, *value); // Insert it. }
Running this program prints nothing on the first run, and “Bjarne: C++ inventor” on all subsequent runs.
The API also allows application-specific metadata to be added to records, provides detailed statistics, supports dynamic resizing of caches, and offers a simple adapter template that makes it easy to store complex user-defined types without the need to clutter the code with explicit serialization and deserialization calls. (In a pinch, if iteration is not needed, the cache can be used as a persistent map by setting an impossibly large cache size, in which case no records are ever evicted.)
Performance
Our benchmarks indicate good performance. (Figures are for an Intel Ivy Bridge i7-3770k 3.5 GHz machine with a 256 GB SSD.) Our test uses 60-byte string keys. Values are binary blobs filled with random data (so they are not compressible), 20 kB in size with a standard deviation of 7,000, so the majority of values are 13–27 kB in size. The cache size is 100 MB, so it contains around 5,000 records.
Filling the cache with 100 MB of records takes around 2.8 seconds. Thereafter, the benchmark does a random lookup with an 80% hit probability. In case of a cache miss, it inserts a new random record, evicting old records in LRU order to make room for the new one. For 100,000 iterations, the cache returns around 4,800 “thumbnails” per second, with an aggregate read/write throughput of around 93 MB/sec. At 90% hit rate, we see a 50% performance increase at around 7,100 records/sec. (Writes are expensive once the cache is full due to the need to evict entries, which requires updating the main cache table as well as an index.)
Repeating the test with a 1 GB cache produces identical timings so (within limits) performance remains constant for large databases.
Overall, performance is restricted largely by the bandwidth to disk. With a 7,200 rpm disk, we measured around one third of the performance with an SSD.
Recovering from errors
The overall design of the thumbnailer delivers good performance when things work. However, our implementation has to deal with the unexpected, such as network requests that do not return responses, GStreamer pipelines that crash, request overload, and so on. What follows is a partial list of steps we took to ensure that things behave sensibly, particularly on a battery-powered device.
Retry strategy
The failure cache provides an effective way to stop the service from endlessly trying to create thumbnails that, in an earlier attempt, returned an error.
For remote images, we know that, if the server has (authoritatively) told us that it has no artwork for a particular artist or album, it is unlikely that artwork will appear any time soon. However, the server may be updated with more artwork periodically. To deal with this, we add an expiry time of one week to the entries in the failure cache. That way, we do not try to retrieve the same image again until at least one week has passed (and only if we receive a request for a thumbnail for that image again later).
As opposed to authoritative answers from the image server (“I do not have artwork for this artist.”), we can also encounter transient failures. For example, the server may currently be down, or there may be some other network-related issue. In this case, we remember the time of the failure and do not try to contact the remote server again for two hours. This conserves bandwidth and battery power.
The device may also be disconnected from the network, in which case any attempt to retrieve a remote image is doomed. Our implementation returns failure immediately on a cache miss for a remote image if no network is present or the device is in flight mode. (We do not add an entry to the failure cache in this case).
For local files, we know that, if an attempt to get a thumbnail for a particular file has failed, future attempts will fail as well. This means that the only way for the problem to get fixed is by modifying or replacing the actual media file. To deal with this, we add the inode number, modification time, and inode modification time to the key for local images. If a user replaces, say, a music file with a new one that contains artwork, we automatically pick up the new version of the file because its key has changed; the old version will eventually fall out of the cache.
Download and extraction failures
We monitor downloads and extractions for timely completion. (Timeouts for downloads and extractions can be configured separately.) If the server does not respond within 10 seconds, we abandon the attempt and treat it it as a transient network error. Similarly, the vs-thumb processes that extract images from audio and video files can hang. We monitor these processes and kill them if they do not produce a result within 10 seconds.
Database corruption
Assuming an error-free implementation of leveldb, database corruption is impossible. However, in practice, an errant command could scribble over the database files. If leveldb detects that the database is corrupted, the recovery strategy is simple: we delete the on-disk cache and start again from scratch. Because the cache contents are ephemeral anyway, this is fine (other than slower operation until the working set of thumbnails makes it into the cache again).
Dealing with backlog
The asynchronous API provided by the service allows an application to submit an unlimited number of requests. Lots of requests happen if, for example, the user has inserted a flash card with thousands of photos into the device and then requests a gallery view for the collection. If the service’s client-side API blindly forwards requests via DBus, this causes a problem because DBus terminates the connection once there are more than around 400 outstanding requests.
To deal with this, we limit the number of outstanding requests to 20 and send another request via DBus only when an earlier request completes. Additional requests are queued in memory. Because this happens on the client side, the number of outstanding requests is limited only by the amount of memory that is available to the client.
A related problem arises if a client submits many requests for a thumbnail for the same image. This happens when, for example, the user looks at a list of tracks: tracks that belong to the same album have the same artwork. If artwork needs to be retrieved from the remote server, naively forwarding cache misses for each thumbnail to the server would end up re-downloading the same image several times.
We deal with this by maintaining an in-memory map of all remote download requests that are currently in progress. If phase 1 reports a cache miss, before initiating a download, we add the key for the remote image to the map and remove it again once the download completes. If more requests for the same image encounter a cache miss while the download for the original request is still in progress, the key for the in-progress download is still in the map, and we hold additional requests for the same image until the download completes. We then schedule the held requests as usual and create their thumbnails from the image that was cached by the first request.
Security
The thumbnailer runs with normal user privileges. We use AppArmor’s aa_query_label() function to verify that the calling client has read access to a file it wants a thumbnail for. This prevents one application from accessing thumbnails produced by a different application, unless both applications can read the original file. In addition, we place the entire service under an AppArmor profile to ensure that it can write only to its own cache directory.
Conclusion
Overall, we are very pleased with the overall design and performance of the thumbnailer. Each component has a clearly defined role with a clean interface, which made it easy for us to experiment and to refine the design as we went along. The design is extensible, so we can support additional media types or remote data sources without disturbing the existing code.
We used threads sparingly and only where we saw worthwhile concurrency opportunities. Using asynchronous interfaces for long-running operations kept resource usage to a minimum and allowed us to take advantage of I/O interleaving. In turn, this extracts the best possible performance from the hardware.
The thumbnailer now runs on Ubuntu Touch and is used by the gallery, camera, and music apps, as well as for all scopes that display media thumbnails.

Hi,
This is probably focused on Ubuntu Touch where it is less of an issue.
One problem that I have with the current implementation of the thumbnails on Ubuntu desktop is the external drivers…. There isn’t any way to delete the thumbnails generated when you plug in a drive or force that they are stored on the drive itself.
From my point of view there is a big security and privacy issue to leave a miniature of everything you have in a drive just because you plug it in once in a computer.
I don’t see a way to DELETE the thumbnail of a existing file.
Shouldn’t that be included?
LikeLike
Well, there is no way for an application to get an image out of the service if that image belongs to a file that is no longer there. That’s because, to get a thumbnail, the caller has to prove that it can read the original file the thumbnail was generated from. A malicious application (on the desktop) could open the database directly though and read its contents. But, considering the kinds of other damage malware can do, thumbnails are probably a low-priority item.
You can always wipe the entire cache with thumbnailer-admin, which deletes the DB contents. But, even with that, leveldb will only mark things as deleted, so a malicious app could examine the raw DB files and, if it can make sense of the layout, still find at least some thumbnails, I suspect.
If you are really worried, use thumbnailer-admin to stop the service and then physically delete the DB files. (Not sure how safe you’ll be with that either, seeing that, if an app gets access to the raw disk, it probably could still see the contents of the deleted files.)
LikeLike
Is there / will there be a way for apps to provide their own thumbnailing services? For instance, the ebook reader Beru creates thumbnails for ebooks but can’t share them with apps like the file browser. It also stores the thumbnails in its own database, with no thoughts about efficiency. I’d much rather let you worry about storing them smartly after I generate them.
LikeLike
Currently, no. We didn’t have this as a requirement. (We did think about it though before we started.) There are two main concerns:
1) If new media formats are to be supported and the thumbnailer is responsible for extracting them, it would probably have to be done via loadable modules. The risk here is that a poor implementation of a third-party image extractor can crash the service, unless we run the extraction out of process. (Doing that is possible of course, but more complex.)
2) To maintain security, the thumbnailer requires proof that the caller can read the original media file before providing a thumbnail, and it generates all thumbnails itself (meaning that it is guaranteed that the thumbnail matches the file contents). An extensible design has to enforce this, but it’s difficult to be sure that the caller isn’t lying: the caller could say “I’m going to thumbnail file X, and here is proof that I’m allowed to read it”, but then go on and conjure up an image that has nothing to do with X. That could create a covert channel across different applications.
I suspect that the more sensible way to support new image sources would be to put the code for this into the thumbnailer itself. That would be pragmatically easier and safer than to add a fancy extensible interface that is difficult to secure.
LikeLike
If I’m understanding correctly, video thumbnails are generated in a separate process. This seems like a better solution for third-party thumbnailers than a loadable module. If it crashes, it would only take down itself. Presumably you could also limit the amount of memory and CPU this process could take, and kill it if it misbehaves.
I understand that there are security implications here, but I’m not convinced these aren’t manageable. If you feed the file to be thumbnailer on stdin and read the thumbnail image on stdout, you could completely disallow file system access for the process. Thus the thumbnailer can’t take notes in a scratch file in hopes of leaking info out through later thumbnails. Network access would obviously be forbidden.
Obviously there’s the risk of ornery thumbnailers creating irrelevant thumbnails, but I think that’s a social problem, not a technical problem, that can be dealt with via ratings and reviews. And it doesn’t seem to be a problem with the current .cache/thumbnails solution, which has significantly less protection.
Adding additional formats to the system thumbnailer is safer, but it doesn’t scale. It could also leave app authors unsure of the capabilities of the thumbnailer. For example, if I add support for a new file type to Beru, I would also have to update the thumbnailer. But if the thumbnailer is a system component, it will take some time to get that code reviewed, merged, QAed, released, and on users’ phones. I’m faced with a few bad choices:
1) Delay my application until most users have the updated system image. (How do I tell?)
2) Release right away, but know that users won’t see thumbnails in my app for some time. (Will they think it broken?)
3) Include the thumbnailer in my app as well, and use it if the system thumbnailer hasn’t been updated. (But if I’m doing that, why bother dealing with the system thumbnailer at all?)
I realize that this is a rather niche feature, so there’s unlikely to be any movement until larger fires are put out. But if you do get to it, please let me know!
LikeLike